SQLite bulk INSERT benchmarking and optimization
2021-02-21(in C#, with Dapper and a bit of Entity Framework Core...)
TL;DR: see the results at the end of this post.
Context
I'm creating a backend service for an application that generates stats for a Last.fm user profile.
To do this, I need to dump the user scrobbles — a point in time when a specific track was played — from the Last.fm api.
After parsing the api response, I have batches of tuples like that:
(string ArtistName, string AlbumName, string TrackName, long Timestamp)

and I want to normalize that into different database tables to avoid duplicating the data.
The process can be executed multiple times and it should not overwrite existing data.
It means I have to do a lot of querying to get existing rows, and then a lot of inserting, or directly use INSERT OR IGNORE statements.
For INSERT OR IGNORE to work, I have simple and composite UNIQUE indexes in place, and I make sure to never insert null values.
Why Entity Framework?
This is the second time I'm doing this.
The first time, I exclusively used Dapper.
This time, I wanted to see if using Entity Framework Core as well could be helpful...
Of course, EF Core is not very suited for fine provider-specific performance tuning, so I'm primarily using it to (re)generate the database schema from my object model.
Low hanging fruits and gotchas
Ask the Internet about SQLite INSERT performance, and the first answer you will get is: wrap multiple INSERTs in a single transaction!
It's is a very good advice, so I will not bother testing independent INSERTs.
There is also a lot of writings about using various PRAGMA directives to trade consistency and safety for performance.
This is your call. I will not explore this route either.
Beware of Entity Framework when benchmarking
EF is supposed to save time, but trying to figure its internal magic can often have the opposite effect, especially when you don't have much experience with it (which is my case).
When doing my benchmarks, I spent hours scratching my head because I saw linear performance degradation from one inserted batch to another, even with a DELETE FROM Table statement in between iterations!
It turned out I was incorrectly reusing my DbContext between iterations, and since it had no idea I manually deleted all the rows, the context was still tracking thousands of entities from previous batches, slowing down each time a little more!
Clearing the table with EF instead of doing it with raw SQL, or recreating the context each time, were two different solutions to the problem.
Benchmarking code
I used the excellent BenchmarkDotNet, along with my actual data model, and actual Last.fm data for testing.
Since I wanted to profile my code, and not my hard drive, I used ImDisk to create a RAMDisk.
All the benchmarks were executed with a database on this RAMDisk.
(I did not use a :memory: SQLite database, because I wanted to be able to open or close connections to it without losing the database)
What to profile?
The need to benchmark became stronger after I came up with different ways to INSERT the same data, and it became hard to know which one was better.
Benchmarking also helped me find even more new ways to do the same thing slightly differently! 🙂
The following is a summary of the different INSERT methods I tested...
Entity Framework
Since I wanted to insert data that may already have been present, and EF Core does not provide a built-in way to do that, I had to query non-existing rows first and then insert.
The actual codes looks like that:
using (var transaction = Context.Database.BeginTransaction())
{
var alreadyExisting =
Context.Artists.Where(x =>
TestData.PrepopulatedAndNewArtists.Select(x => x.Name).Contains(x.Name))
.ToDictionary(x => x.Name);
var toInsert =
TestData.PrepopulatedAndNewArtists
.Where(x => alreadyExisting.ContainsKey(x.Name) == false)
.Select(x => new Artist { Name = x.Name });
Context.Artists.AddRange(toInsert);
int inserted = Context.SaveChanges();
transaction.Commit();
}
Dapper loop INSERT
This is a simple INSERT OR IGNORE prepared statement, run within a loop for each row I want to insert :
using (var transaction = Context.Database.BeginTransaction())
{
var nameColumn =
Context.GetColumnName(Context.Artists.EntityType, nameof(Artist.Name));
int inserted = 0;
foreach (var item in TestData.PrepopulatedAndNewArtists)
{
inserted += Context.Database.GetDbConnection().Execute($@"
INSERT OR IGNORE INTO {Context.Artists.EntityType.GetTableName()}
({nameColumn})
VALUES (@Name)",
new { Name = item.Name });
}
transaction.Commit();
}
The table name is added dynamically instead of being hard-coded, because I want to keep it working if I decide to rename my entities and regenerate the database...
Dapper bulk INSERT
This is a slight variation from the previous method. Instead of looping in my code, I give Dapper all the rows up-front, and let it loop internally:
using (var transaction = Context.Database.BeginTransaction())
{
var nameColumn =
Context.GetColumnName(Context.Artists.EntityType, nameof(Artist.Name));
var inserted = Context.Database.GetDbConnection().Execute($@"
INSERT OR IGNORE INTO {Context.Artists.EntityType.GetTableName()}
({nameColumn})
VALUES (@Name)",
TestData.PrepopulatedAndNewArtists.Select(x => new { Name = x.Name }));
transaction.Commit();
}
This is actually significantly faster than manually looping!
Dapper CTE INSERT
Using a Common Table Expression here is a bit of a hack to be able to do everything in one query.
There is an alternative syntax for simple inserts (see the multi-values section) but it does not work on old SQLite versions...
Basically, the following boils down to a prepared statement with all the parameters being provided separately:
INSERT OR IGNORE INTO Artists
(Name)
SELECT * FROM
(WITH Cte(Name) AS
(VALUES (@a1),(@a2),(@a3))
SELECT * FROM Cte) Cte
I also tried to write another more complicated version of that, with a sub-query and JOINs in an attempt to insert things without querying them first, hoping it would beat the simple insert loop...
Spoiler: being ugly is not its only problem. It's very slow as well!
...It dit not beat the simple loop.
There is also a very real risk of hitting SQLITE_MAX_VARIABLE_NUMBER (set to 32766 on recent versions of SQLite) on big batches, or medium ones with many columns.
Dapper Multi-values INSERT
This is the modern syntax to replace the CTE from the previous section and send the query and its many parameters in one go.
It's a bit faster than the CTE, but also subject to SQLITE_MAX_VARIABLE_NUMBER...
INSERT OR IGNORE INTO Artists
(Name)
VALUES ((@a1),(@a2),(@a3))
ADO.NET DbCommand
Inspired by this question and answer on Stack Overflow, I also benchmarked a low level DbCommand implementation, that can re-use the parameters efficiently. It's tedious, but I doubt it can go faster than that!
I first wrote an ugly but short(ish) hard-coded implementation, then a slightly prettier and significantly longer generic version.
The generic version is based on ValueTuple to enforce that the columns tuple and the values tuples have the same arity:
// Generic public methods enforcing the same arity for the columns and values:
public int InsertOrIgnore<TItem1>(
IEntityType entityType,
string targetPropertyNames,
IEnumerable<TItem1> values)
=> InsertOrIgnoreImplementation(
entityType,
ValueTuple.Create(targetPropertyNames),
values.Select(x => ValueTuple.Create(x)));
public int InsertOrIgnore<TItem1, TItem2>(
IEntityType entityType,
(string, string) targetPropertyNames,
IEnumerable<(TItem1, TItem2)> values)
=> InsertOrIgnoreImplementation(entityType, targetPropertyNames, values);
public int InsertOrIgnore<TItem1, TItem2, TItem3>(
IEntityType entityType,
(string, string, string) targetPropertyNames,
IEnumerable<(TItem1, TItem2, TItem3)> values)
=> InsertOrIgnoreImplementation(entityType, targetPropertyNames, values);
public int InsertOrIgnore<TItem1, TItem2, TItem3, TItem4>(
IEntityType entityType,
(string, string, string, string) targetPropertyNames,
IEnumerable<(TItem1, TItem2, TItem3, TItem4)> values)
=> InsertOrIgnoreImplementation(entityType, targetPropertyNames, values);
// Private actual implementation:
private int InsertOrIgnoreImplementation<TTuple>(
IEntityType entityType,
ITuple targetPropertyNames,
IEnumerable<TTuple> values) where TTuple : ITuple
{
// Local helper methods
static IEnumerable<object> GetTupleItems(ITuple tuple)
{
for (int i = 0; i < tuple.Length; i++)
yield return tuple[i];
}
static string GetColumnName(IEntityType entityType, string targetPropertyName)
=> entityType
.FindProperty(targetPropertyName)
.GetColumnName(StoreObjectIdentifier.Table(
entityType.GetTableName(), entityType.GetSchema()));
var columnNames =
GetTupleItems(targetPropertyNames)
.Cast<string>()
.Select(x => GetColumnName(entityType, x))
.ToList();
var formattedColumnNames = string.Join(',', columnNames);
var formattedParameterizedColumnNames =
string.Join(',', columnNames.Select(x => $"@{x}"));
var command = Database.GetDbConnection().CreateCommand();
command.CommandText = $@"
INSERT OR IGNORE INTO {entityType.GetTableName()}
({formattedColumnNames})
VALUES ({formattedParameterizedColumnNames})";
// Create parameters with their names:
var parameters = columnNames.Select(x =>
{
var parameter = command.CreateParameter();
parameter.ParameterName = x;
command.Parameters.Add(parameter);
return parameter;
}).ToList();
int inserted = 0;
// Execute the command, reusing the parameters:
foreach (var tuple in values)
{
for (int i = 0; i < columnNames.Count; i++)
{
parameters[i].Value = tuple[i];
}
inserted += command.ExecuteNonQuery();
}
return inserted;
}
Benchmark results
Here is a screenshot of the benchmark results:
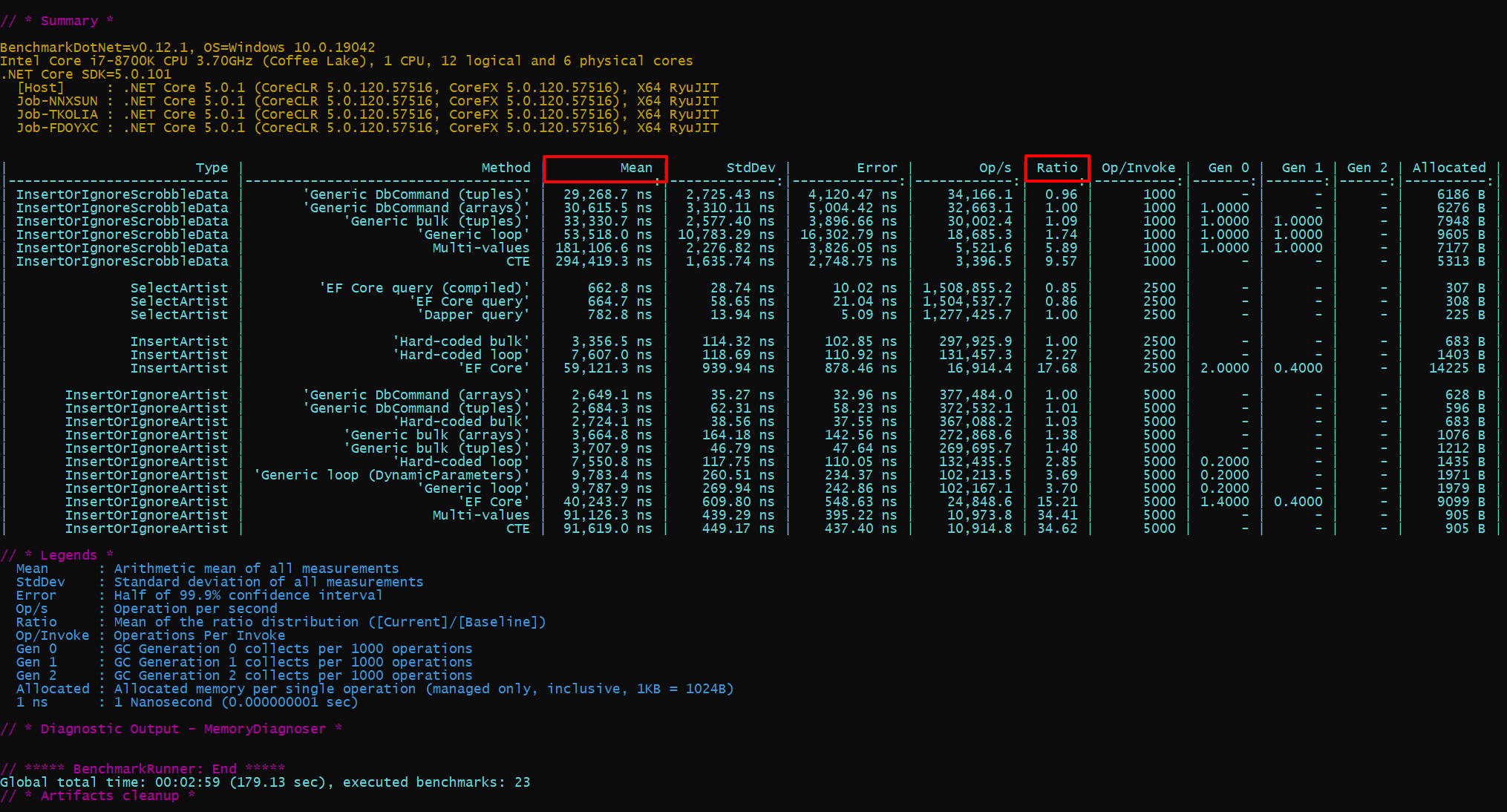
You can also see the html report here
Reminders:
- Benchmarks on the
Artiststable only have to do with a singleNamecolumn with aUNIQUEindex. - Benchmarks on the
Scrobblestable involve more computing, and end up inserting three columns (UserId,TrackId,Timestamp) with a compositeUNIQUEindex on them. - I got these numbers with a database on a RAMDisk.
Notes:
- The
Op/Invokecolumn is the number of attempted INSERTs or SELECTs for one iteration of the benchmark. All the timings are divided by this number, so fixed initialization costs are spread along. INSERT OR IGNORE INTO Artistsbenchmarks have half their data to insert already in the database, hence 5000 operations per invoke instead of 2500 for other related benchmarks.- The baseline for the
Ratiocolumn is manually set to the expected fastest method for each benchmark category.
Analysis
INSERT performance
Without any surprise, the fastest way to INSERT OR IGNORE data with SQLite is by using a DbCommand and reusing the parameters.
It's not significantly faster than executing the same query with Dapper though (between about 1.1x and 1.4x faster, and I suspect I did not fully optimize this second number).
As I mentioned previously, bulk inserts with Dapper (compared to a loop) are notably faster, and it's easy to switch between the two. It's an easy win!
CTE and multi-values insertions perform very badly compared to other methods (Event EF Core!). I figure this is due to the number of prepared parameters SQLite — and/or the provider — have to deal with in these cases...
SELECT performance
EF Core is faster than Dapper on a simple query!
The difference is not really significant, especially since it's a very cheap query, but still, it's worth pointing out...
Fin
The full benchmark code is currently not available publicly, because I'm lazy and I don't want to maintain a repo just for that.
There is a good chance I publish it along with the associated Last.fm stats projects this is all about, once it's more complete...
EDIT: There it is!
https://github.com/mlaily/lastfmstats/tree/master/src/Benchmark
The comment is shown highlighted below in context.
JavaScript is required to see the comments. Sorry...